Uso Claude Code ogni giorno. È il mio terminale “smart”: gli chiedo di cercare un prezzo da un fornitore, di lanciare un report, di scrivere un piccolo script, e lui esegue. Per farlo ho creato nel tempo una sessantina di skill — istruzioni ricamate su misura per ognuno dei miei workflow ricorrenti.
A un certo punto mi sono accorto che qualcosa non tornava.
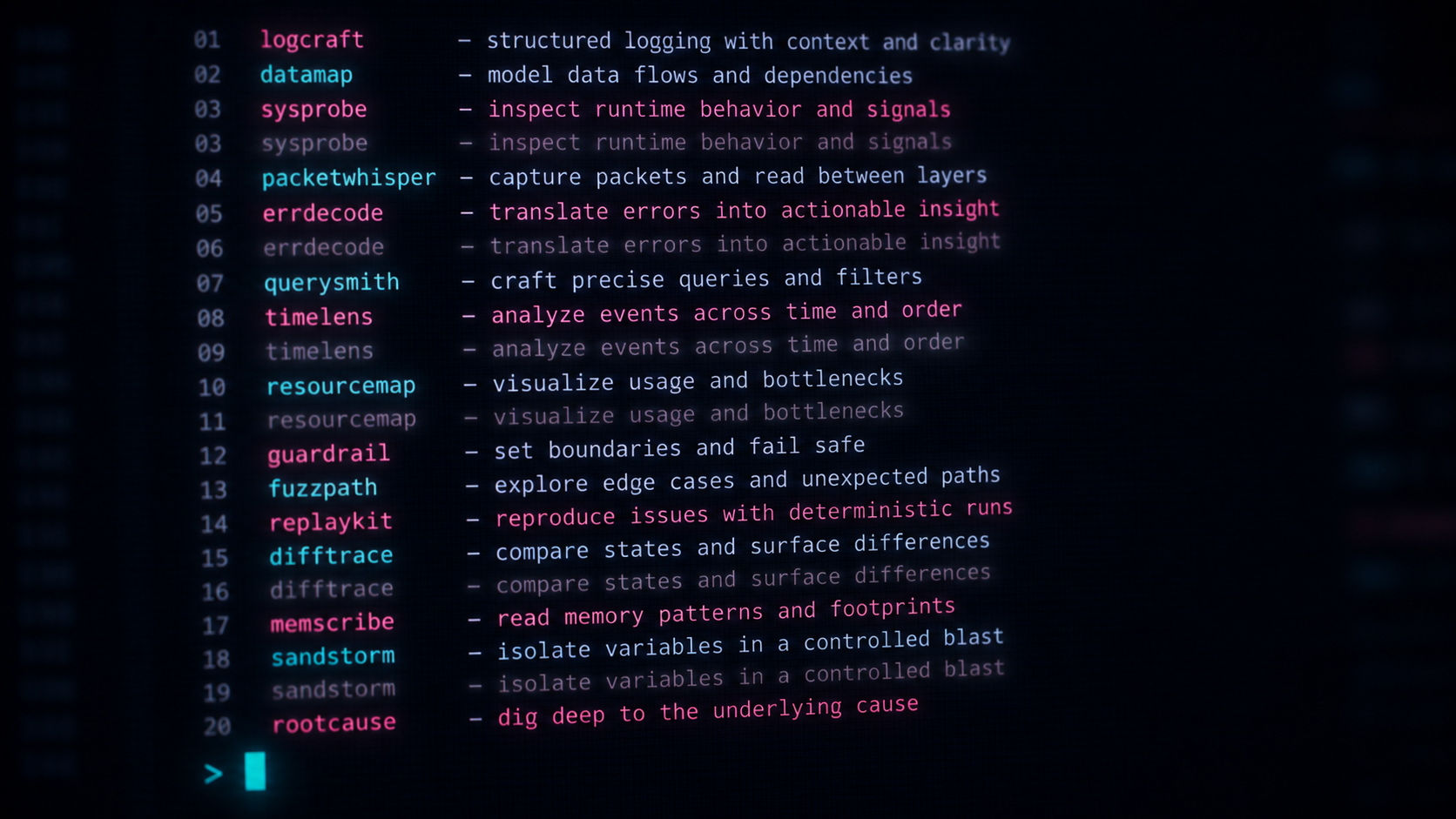
Ogni volta che aprivo una nuova chat, Claude mi presentava un elenco di skill disponibili. Solo che invece di sessanta, ne contava più di cento. E la cosa peggiore: molte erano elencate due volte, identiche, riga per riga.
vendor-acme — Cerca prodotti, scarica fatture e ordini dal distributore.
vendor-acme — Cerca prodotti, scarica fatture e ordini dal distributore.
(Negli esempi di codice di questo post uso vendor-acme come nome fittizio al posto dei miei fornitori reali — la sostanza tecnica non cambia.)
Sembra una cosa da poco. In realtà non lo è.
Perché un listing gonfio costa soldi
Le skill in Claude Code funzionano così: il sistema legge la descrizione di ogni skill che hai (una riga di testo) e la mette nel prompt di sistema, all’inizio di ogni messaggio. Serve perché il modello sappia “cosa può fare” e decida di attivare la skill giusta quando glielo chiedi. Se hai sessanta skill, sono sessanta righe in più nel prompt. Se per qualche motivo ne diventano centoquindici, sono centoquindici. A ogni messaggio. Per tutta la sessione.
Quei token li paghi tu, anche se non li usi mai. E nei messaggi successivi rendono il modello un po’ meno preciso, perché la sua “memoria di lavoro” è già occupata da roba che potrebbe ignorare.
Detto in altre parole: avevo un leak di context. Volevo capire da dove arrivava.
Il mio setup, in tre parole
Per spiegare il caso devo dire come ho organizzato le skill. Il mio è un setup un po’ barocco, perché uso più tool AI insieme (Claude Code, Codex, Gemini CLI, Hermes, Antigravity, OpenCode) e voglio che leggano tutti dalle stesse skill, senza copiarle in cinque posti diversi.
La fonte unica è il mio vault Obsidian:
~/obsidian-vault/SecondBrain/skills/
├── vendor-acme.md
├── vendor-beta-scraper.md
├── ricerca-fornitori.md
└── ... altre cinquanta
Da qui le skill si propagano agli altri tool tramite vari symlink e copie. Per Claude Code in particolare la catena è:
- Vault → file
vendor-acme.md(la verità) - Symlink
~/claude-skills/→ vault - Wrapper
~/prezzismart-lib/skills/vendor-acme/SKILL.md→ uno stub che dice “leggi~/claude-skills/vendor-acme.md” - Symlink
~/.claude/skills/vendor-acme→ wrapper
L’ultimo path è quello che Claude Code apre davvero. Sembra contorto, ma ognuno di quei livelli serve un tool diverso.
Il sintomo
Apro Claude Code, lancio una nuova chat e leggo il listing iniziale. Conto: circa 115 voci di skill. So che la mia lista vera ne ha circa sessanta. Confronto velocemente: trentadue compaiono due volte ognuna. Tutte le altre — circa una trentina — compaiono una volta sola.
Le trentadue duplicate sono guarda caso quelle “vecchie”, quelle nate prima del refactoring del repo. Le altre, quelle più recenti, no.
Primo sospetto: forse Claude Code legge le skill da due posti, e le trentadue stanno in entrambi.
La caccia, primo round: il filesystem
Inizio dal banale. Listo le directory rilevanti:
ls ~/.claude/skills/
ls ~/claude-skills/
ls ~/prezzismart-lib/skills/
E mi accorgo che ~/claude-skills/ non è un repo separato come pensavo: è un symlink al vault Obsidian. La scoperta non spiega niente da sola, ma riduce il quadro.
Tutti i symlink in ~/.claude/skills/ puntano correttamente ai wrapper. Niente di strano. Eppure il listing duplica. Quindi il duplicato non viene da una doppia entry in quella directory.
Cerco se ci sono altre dir nascoste che Claude Code potrebbe scansionare:
ls ~/.claude/
E mi salta all’occhio una voce inattesa:
~/.claude/commands → ~/obsidian-vault/SecondBrain/skills
Un altro symlink al vault. Creato il 13 aprile dell’anno scorso, all’epoca di una migrazione del setup. Non lo ricordavo nemmeno. Era un retaggio di quando le skill erano “slash commands” in Claude Code (vecchio nome) e finivano in commands/.
Sospetto fortissimo: Claude Code sta leggendo skill sia da ~/.claude/skills/ (i wrapper) sia da ~/.claude/commands/ (il vault, accesso diretto). Le trentadue skill che esistono in entrambi vengono caricate due volte.
La caccia, secondo round: il binario
Per essere sicuro, voglio leggere come Claude Code carica davvero le skill. Il binario è un eseguibile compresso da 237 MB:
file ~/.npm-global/lib/node_modules/@anthropic-ai/claude-code/bin/claude.exe
Niente sorgenti pubbliche per quella parte, ma il binario è un bundle JavaScript minificato — strings mi tira fuori abbastanza per capire la logica. Estraggo i pattern interessanti:
strings claude.exe | grep -E "skills/|claude-skills|loadSkills"
E trovo la funzione di discovery, che minificata dice in sostanza:
Loading skills from:
managed = ${MANAGED_DIR}/skills
user = ~/.claude/skills/
project = ${CWD}/.claude/skills/
legacy = ~/.claude/commands/ ("DEPRECATED")
Eccolo. Il path ~/.claude/commands/ è marcato DEPRECATED ma viene ancora caricato. E poi c’è un dedup, ma confronta i file per realpath: due path che puntano a file fisicamente diversi (anche se il contenuto sarebbe equivalente) non vengono dedotti.
Nel mio caso:
~/.claude/skills/vendor-acme/SKILL.md→ wrapper-stub (file A)~/.claude/commands/vendor-acme.md→ file vault, contenuto vero (file B, attraverso il symlink)
Sono due file diversi con lo stesso name: vendor-acme nel frontmatter. Per Claude Code sono due skill distinte.
Il fix
Una sola riga:
rm ~/.claude/commands
Rimuovo il symlink legacy. Le skill restano accessibili attraverso la catena pulita (~/.claude/skills/ → wrapper → vault). Hermes, Codex e gli altri tool non sono toccati: usano path propri.
Riapro Claude Code. Listing iniziale: circa 60 voci. Niente più duplicati. Risultato visibile in tempo reale, niente bisogno di restart globale.
Ho conservato il pointer del symlink in un file di backup, così se mai dovessi tornare indietro mi basta:
ln -s "$(cat ~/skill-restyling-backup-2026-05-03/.claude-commands-symlink-target)" \
~/.claude/commands
Tempo totale dell’intervento, dall’identificazione del sintomo al fix verificato: poco più di due ore. Quasi tutte di indagine — il fix in sé è una riga.
Cosa ho imparato (e che vale per chiunque tenga skill su Claude Code)
1. Il listing skill è un costo nascosto
Ogni skill che hai ti costa una riga di descrizione nel prompt di sistema, a ogni messaggio, per tutta la sessione. Sessanta skill non sono un problema. Centocinquanta cominciano a esserlo, soprattutto se la conversazione è lunga.
Tieni il numero sotto controllo. Se hai duplicati o skill che non usi più, archivia. Non c’è nessun beneficio a tenerle attive “perché non si sa mai”.
2. La descrizione è un trigger, non un riassunto
La descrizione è l’unica cosa che il modello vede a freddo, e la usa per decidere quando attivare la skill. Se quattro skill hanno descrizioni quasi identiche (perché coprono quattro siti dello stesso settore con la stessa funzione), su una query generica il modello rischia di attivarne tre o quattro insieme. Ognuna mangia altri token.
La regola che mi sono dato: ogni descrizione deve avere un marker univoco esplicito. Per le skill che coprono lo stesso tipo di sito, ho riscritto tutte le descrizioni con il prefisso USE ONLY quando l'utente menziona esplicitamente "<nome>". Per le skill di sourcing che hanno un orchestratore unificato sopra, il prefisso è Per ricerca multi-fonte preferire l'orchestratore. Usare questa skill SOLO per <azione specifica>.
Sembra ridondante, ma cambia drasticamente quanto spesso una skill sbagliata si attiva.
3. Symlink di un anno fa sono scheletri nell’armadio
Ogni volta che aggiungi un alias “per comodità” stai creando un punto in cui il sistema può comportarsi in modi inattesi. Nel mio caso era un symlink innocuo creato durante una migrazione che ho dimenticato. Ha vissuto in pace per dodici mesi e poi ha iniziato a costarmi soldi.
Lezione: ogni volta che crei un symlink, scrivilo da qualche parte. Io ora ho una memoria persistente con scritto “non ricreare mai più ~/.claude/commands come symlink al vault” — così la prossima volta che mi viene la tentazione, la istanza AI che mi assiste mi ferma.
4. Quando il dedup interno non basta, non basta
Il binario di Claude Code ha già un meccanismo di deduplica. Funziona per realpath: se due path puntano allo stesso file, ne tiene uno solo. Non è abbastanza, perché due wrapper “equivalenti” come body ma con file diversi sfuggono.
Avrei potuto evitarlo dall’inizio se le skill native e i wrapper fossero stati lo stesso file (un solo posto, una sola fonte). Ma allora avrei perso la possibilità di esporre le skill anche agli altri tool. Tradeoff classico.
5. Strings + grep batte i ticket di support
Il binario è minificato, illeggibile a vista. Ma strings + grep trovano i pattern strutturali in pochi secondi. Per capire da dove un sistema legge i suoi config, il binario stesso è quasi sempre la fonte autorevole più veloce di qualsiasi documentazione o issue tracker.
Il bilancio della sessione
Mentre ero lì, già che avevo le mani in pasta:
- 4 skill dismesse (non le usavo più o erano duplicate funzionali di altre)
- 3 anomalie sistemate (file solitari, drift di pattern)
- 12 descrizioni riscritte per ridurre i trigger ambigui
- Backup tar completo dei tre layer di skill prima di toccare niente, archiviato in
~/skill-restyling-backup-2026-05-03/
E un documento di architettura completo nel mio vault Obsidian, che spiega come tutto è collegato — così la prossima volta che dovrò rimettere le mani in questo sistema (o spiegarlo a un’altra istanza AI), non dovrò ricostruire tutto da zero.
Il listing pulito mi è già visibile nelle nuove sessioni Claude Code. Ho recuperato la metà del context iniziale e ho tagliato il rumore che mi disturbava le decisioni del modello sulle query ambigue.
Se anche tu hai un setup multi-tool con vault Obsidian (o simili) che fa da hub per le tue skill AI, controlla ~/.claude/commands e vedi se è un symlink al posto sbagliato. Si fa in dieci secondi. E magari risparmi qualche centinaio di migliaia di token al giorno.